Metrics Notes
Table of contents
Entropy
(Credit: ML Mastery)
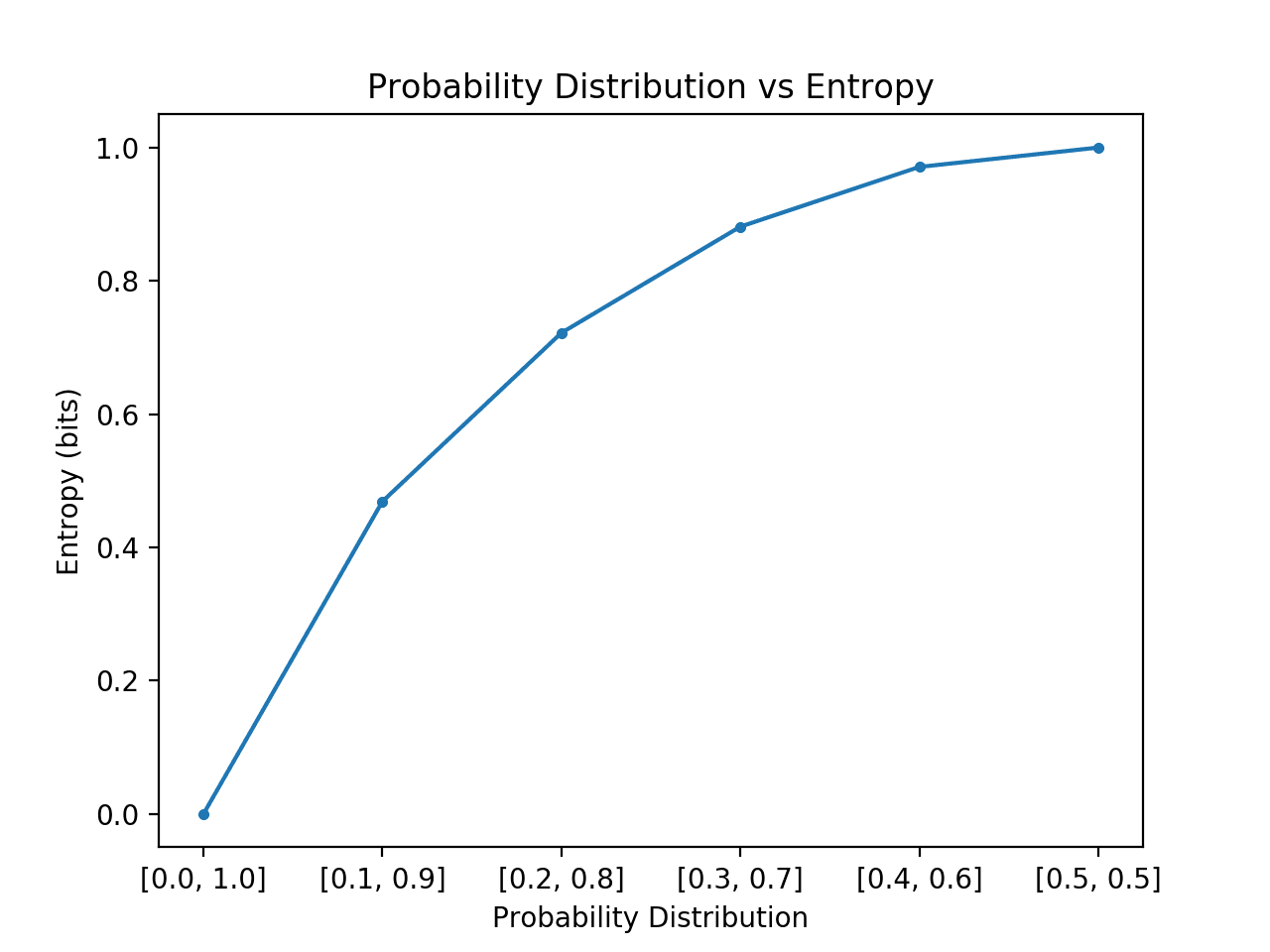
An information content or uncertainty measurements. The higher the entropy, the harder to predict value of an random variable from a given distribution.
The entropy of a discrete random variable with distribution consisting of states is:
Intuitions
For example, let be a random variable from distribution : over states.
If we have three random variables from three corresponding dist. .
| k | |||
|---|---|---|---|
| 0.25 | 0.75 | 0.5 | |
| 0.75 | 0.25 | 0.5 |
Intuitively speaking, according to the given information, the prediction of and should be with higher confidence than :
- In case: we could somewhat predict that should likely to be observed. Likewise, it’s for
- However, for it’s impossible for any prediction (50:50).
Is there anyway to define a measurement to how “confident” our prediction would be with given information about states? By dividing and conquer this question, the sub question should be:
How to measure the prediction’s confidence for a given state
- is said to have low entropy, or rich amount of information; if using we could easily predict a specific event of
Perplexity
To measure “predictability”. Given is a uniform dist. over state
References
- Murphy, K. P. (2022). Probabilistic Machine Learning: An introduction. MIT Press. probml.ai